最近看到日本有几个人一直在搞足球游戏的AI。自大数据在足球广泛开展以来,他们近期也用上了当下的tracking data来学习可以代替原本基于规则的智能体。不妨可以按时间线来看看他们都做了啥,对于足球的游戏环境做了什么特殊的设置。
# 2011年:《Believable Team Behavior: Towards Behavior Capture AI for the Game of Soccer》
# 2014年:《Creating Believable and Effective AI Agents for Games and Simulations: Reviews and Case》
# 2019年:《Pass in Human Style: Learning Soccer Game Patterns from Spatiotemporal Data》
# 2020年:《Learning Believable Player Movement Patterns from Human Data in a Soccer Game》
作者Maxim Mozgovoy和Iskander Umarov,来自日本会津大学和TruSoft公司。
首先看他对believable的定义,“a believable agent possesses human-like characteristics, such as capabilities to learn, to show doubts (by delaying decision making), to make mistakes, and to adjust own strategy in response to opponent’s actions.” 这意思,应该就是对现有的基于深度学习、机器学习和强化学习的AI的一个特征描述吧大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!。
像足球这样的游戏,整个团队需要表现出自己的“团队风格” ,这是agent需要做的。
本文采用的环境: 本文的核心是从数据中借助BC(监督学习)学习人类的模式,因此一个部分是学习,另一个部分是执行。在本文的足球模拟器中,单个球员的动作仅限于沿八个可能方向的移动,传球和踢向球门线。
本文的核心是从数据中借助BC(监督学习)学习人类的模式,因此一个部分是学习,另一个部分是执行。在本文的足球模拟器中,单个球员的动作仅限于沿八个可能方向的移动,传球和踢向球门线。
2. 怎样执行动作?有下面几种场景需要考虑。
1) 控制持球球员。BC智能体仅附加到当前拥有球的球员身上。当球移至另一名球员时,BC智能体将对其进行控制。所有其他参与者都由默认的(基于规则)AI系统控制。
2) 控制整个球队。存储在知识库中的原子动作要包含各个参与者的所有动作。
3) 控制所有持球球员。BC智能体分别控制场上的每个球员。
第一种情况很方便,使用“带球球员”可以用来测试BC方法在足球比赛中的适用性,避免了与团队行为有关的复杂性。
第二种情况本文认为不适合做,因为其要利用基于情形的的推理子系统试图找到当前游戏的最佳匹配,并作出决策,用一个团队作为一个智能体,决策空间太大。并且当要处理少一人(红牌)的情形时还需要特别考虑。
本文认为最重要的实验是第三种情况。
3. 知识(状态)表示
这里大概翻译一下
状态和动作存储在数据结构GameSituation和Action中。 GameSituation结构存储由开发人员选择的最重要的足球领域属性的值。游戏状态是基于特定BC Agent的,因此BC Agent的最重要属性以更高的精度存储,而其他属性(例如遥远玩家的位置)则用粗略估计来表示,甚至省略。每个动作对象都存储执行相应游戏动作所需的参数。每个“动作”均指单个足球运动员的活动。
在遇到新情形时,智能体会记住传入(GameSituation,Action)对,并在后续记录之间创建链接,从而形成一个包含动作链的有向图式知识库大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!。
每个动作链对应于某个特定的游戏会话。除了核心动作参数外,每个动作对象还包含一个使用情况计数器,每次相同的(GameSituation,Action)对到达输入时,该计数器就会增加。此计数器随后用于加权操作选择(在可能的情况下,更频繁地选择更频繁的操作)。
决策机制比学习子系统要复杂,因为它包含一个附加的启发式搜索例程。理想情况下,当智能体从游戏引擎接收到下一个GameSituation对象时,它应该从知识库中提取相同的GameSituation。但是,为了获得可靠的决策,不能假设此搜索总是成功的。因此,稚嫩那个题应该能够从知识库中提取最接近的(如果不是完美的)匹配,并根据找到的(GameSituation,Action)对进行操作。
在该系统中,通过一系列具有顺序松弛搜索条件的知识库投票测验来实现近似匹配。有两种类型的松弛方式:(a)从比较中排除某些开发人员指定的GameState属性; (b)进行近似比较(如果属性的差异小于某个开发人员指定的值,则认为这些属性相等)。
4. 动作筛选子系统和规划筛选
也大致翻译下,这里过滤器的意思就是把不合理的动作用规则给过滤掉。
由基于情形的推理模块在决策过程中检索到的相关动作,通过动作过滤器系统来进一步缩小范围。动作筛选器通过向Agent提供有关游戏基本原理的简单提示来提高决策质量。单个动作过滤器会分析所有由动作选择子系统提取的动作,并拒绝某个动作(标记为不可接受)或降低其权重(如果它不符合某些预先编程的标准)。
例如,基于情形的推理系统可能会认为当前的游戏情况GS1与在知识库中找到的游戏情况GS2相似,比如,在GS2中成功执行的“传球”动作可能在GS1中执行会有风险(即传不成功)。即使比赛情况之间的差异可能很小,它们对于给定的传球动作也可能至关重要:一名防守队员的小幅坐标变化可以使传球容易被拦截。所以对于足球比赛,本文决定开发一个特殊的规划程序过滤器,将基本的规划功能引入该系统(基于规则)。相比之下,足球需要一些预先规划,并意识到所选动作的可能结果。
规划过滤器的工作原理如下。首先,它构造了表示当前分析动作A可能结果的游戏状况GSnew。换句话说,它试图在执行动作A之后猜测游戏场上的状况。由于A包含有关BC智能体预期动作的所有信息,因此系统可以预测代理属性的更改;而对手和球的新位置则是使用他们当前的速度和方向来推断。然后,筛选器检查基于情形的推理子系统是否可以提取GSnew的动作。如果所有这些动作都被动作过滤器子系统拒绝,则预测的游戏情况GSnew被认为是不利的,则规划控制器可以降低A的权重。(其实是RL里面的model-based思想)
由于存储在知识库中的游戏图包含智能体的未来动作序列,因此规划过滤器可以使用此信息来预测在智能体的整个动作链之后可能发生的游戏情况。在实际实验中,将规划者的视域(即前向的规划长度)限制为某个基于时间的值(通常为2-3秒)。
5. 实验
1)首先,确定了16个参数来描述了单个球员(智能体)的状态。其中最重要的是:
玩家的位置(坐标);
“前进危险”值,表示在向对手目标前进的下一步中丢球的可能性;
朝向对手最近的玩家的方向和距离;
玩家当前的移动方向;
球的状态(空中/球员拥有);
拥有球的球员的位置。
此参数集形成所谓GameSituation数据结构。第一个实验是只控制带球球员,旨在证明系统踢足球的能力。控球的人类专家打了8000帧比赛时间(约400秒)。然后在人类提供的数据的2000、4000、6000和8000帧样本上训练了两个不同的BC Agent(BC1和BC2)。然后,使用三个指标比较了BC1和BC2控制的智能体的性能:
每2000帧比赛的平均进球数;
每2000帧比赛被对手球队截取的平均传球次数;
每2000帧比赛中,球员拥有球队球的平均百分比。
其余的团队成员以及对手的玩家都由一个简单的基于规则的AI系统控制。结果(参见下图)显示BC智能体可以较好地重现人类生成的行为模式。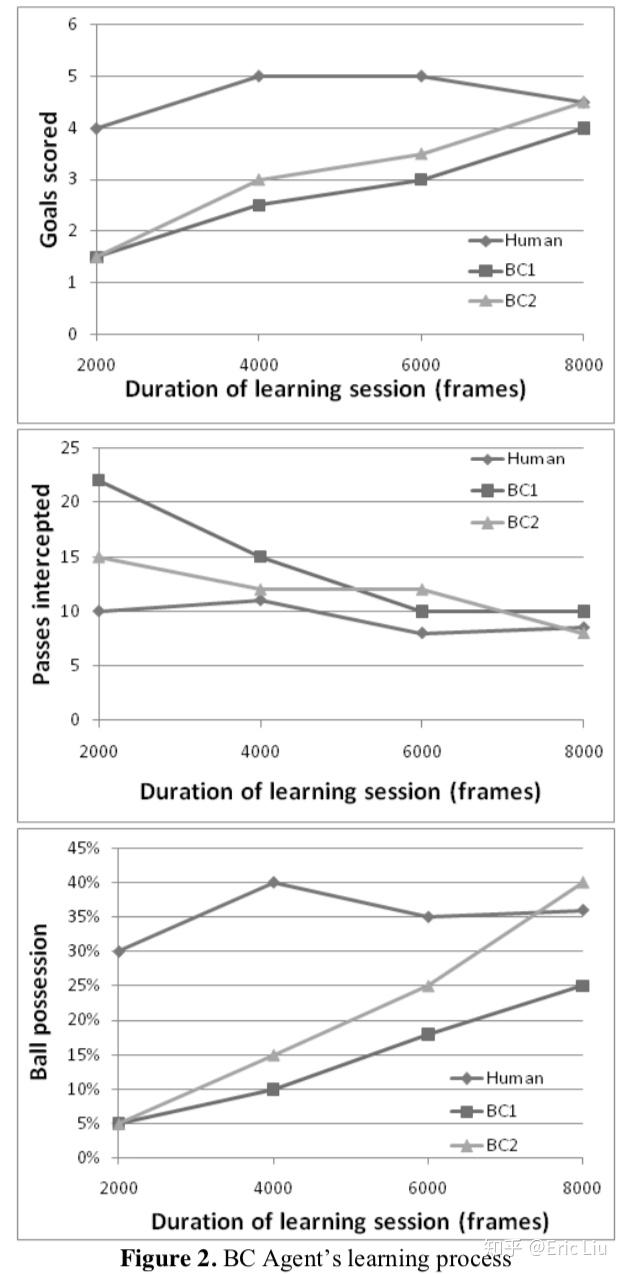
2)下一个目标是分别独立控制所有智能体,以获得believable的团队行为。可能要检查的最重要指标是算法的健壮性,即算法在变化的条件下能够重现团队行为模式的能力。
实验如下进行。五名独立的人类专家通过网络接口控制各自的足球队队员。每台计算机都运行同一足球模拟器的本地副本,并且游戏在本地网络上同步。玩了几场比赛(每场5-10分钟),然后分析了BC特工的团队行为。(此类实验有些技术难度:即使人类专家也需要进行一些预培训,然后他们才能有效地开展团队合作。他们还需要在战术上达成一些初步协议,并在各种游戏场景中使用精心设计的配合。)
实验结果是,独立控制的BC智能体团队可以复制出人类专家的相对复杂的配合。其中,每个智能体的GameSituation都包含拥有球的球员位置。如果BC智能体团队进行进攻,则该球队拥有球,因此所有BC智能体均与持球球员同步。
由BC特工队(玩家P1-P5,详见下图)可以重现的最复杂的配合之一,包括以下过程:
1. P5拦截O5并得到球。
2. P5将球传给P4,以避免O5的铲球。
3. P4将球传给后卫P2,完全避免了被O5解围的危险
4. P2进行短跑,然后将球传到P3。同时,P4移向游戏场的中心,P5跑向对手的球门。
5. P3将球返回到P2。
6. 此时,O5不再对P4构成威胁,因此P2将球传给P4。
7. P4迅速将球进一步传送到P5。
8. P5进球。
可以看出,为了进球团队需要付出大量努力,包括严格同步执行的行动。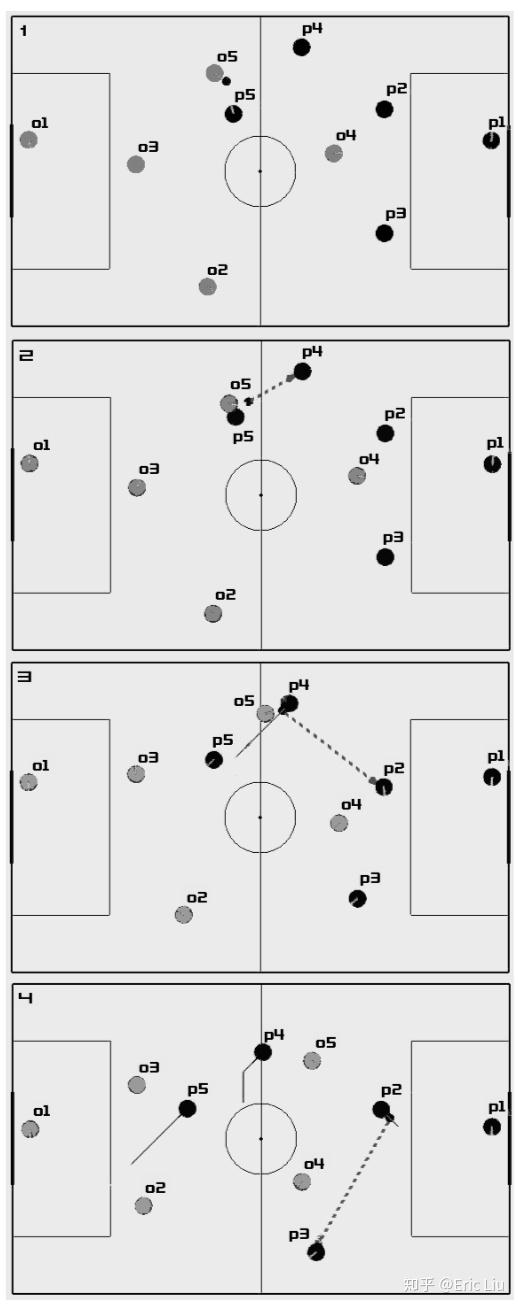
一句话总结来说就是借助专家的示例数据,让智能体学习专家的踢球方式,变得更像人。感觉做这个,主要还是很多工程上的工作以及写了带有很多特定的领域知识的内容吧,比如筛选器,还有状态、动作的定义,都要依靠人工预先设定的较好,才可以有比较好的效果。
作者Iskander Umarov和Maxim Mozgovoy,来自TruSoft公司和日本会津大学。
作者Victor Khaustov, Georgii Mola Bogdan and Maxim Mozgovoy,来自日本会津大学的“Active Knowledge Engineering Lab ”,发表在2019 IEEE Conference on Games (CoG),其实内容很少,简要摘一下重点。
本文基于的游戏环境是《Programming Game AI by Example》这本书里的经典案例—— SimpleSoccer(2D的足球环境)。
本文主要是要从过往的真实比赛的轨迹数据中学习传球行为,这样学习出来的智能体可能更接近人类,因此在玩游戏的时候体验可能会更好。
一个难点是tracking data数据集的有限程度,其中的各种行为,例如射门、传球等可能都会比较稀疏,而且一个球队一个赛季只会参加几十场比赛。因此如果要计划学习特定团队的行为模式,将不得不依靠少量数据样本,尤其是在处理相对罕见的比赛事件时。对于学习传球行为,可以期望一个职业球队平均每场比赛获得365-370次传球。
在此考量下,借用先前工作采用的基于case-based reasoning decision making 以及 Markov chain-like database of human actions相结合的学习框架,即,智能体的知识用图(graph)来表示,将各个游戏情况作为顶点,将动作作为加权边(其实就是马尔科夫决策过程MDP)。智能体可以借助某个动作,从状态A变成状态B。决策算法尝试找到当前游戏情况的最佳匹配并采取相应决策。
所以核心其实在于本文怎么建模所谓智能体的状态也就是游戏情形的呢大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!?
为了学习传球行为,本文将智能体的每个状态都表示为以下属性的集合:
• 球员与球(传球者)在18×10网格中的坐标。
• “前进威胁”启发式估计,范围为0到5(取决于在向前方向上与最近的对手的距离)。
• 传球者当前的运动方向(支持8个方向)。
• 最接近的对手的方向(0-7)(从传球者的角度来看)。
• 距离最近的对手的距离(从传球者的角度来看),范围为0到2。
• “最安全的传球威胁”启发式估计,范围为0到5(取决于队友和对手的位置)。
• “最安全的前向传球威胁”启发式估计,范围为0到5。
• 布尔属性,指示找到至少一个安全的传球(威胁估计为0-2)。
本文针对的每个要学习的动作都是传球动作,其内容其实是传球方和接球方的坐标。
在决策过程中,系统将尝试找到这些属性的完美匹配,如果找到,则传球。如果未找到任何动作或它们在给定的上下文中不适用(传球方和接球方的实际坐标与数据结构中的值明显不同,即不是传球场景),将使用内置的AI控制智能体。
实验部分,数据集是STATS先前开放的Soccer Dataset(不过现在似乎找不到了),其内容是欧洲几千场足球比赛的真实tracking data(就是每场球的所有球员和球的二维坐标)。
实验内容:用AI对战测试出来的传球数据比对真实数据中传球数据。
两个表分别是长度和方向的分布。
实验2,将传球距离和传球方向作为向量,比较平均的余弦相似度。如下表。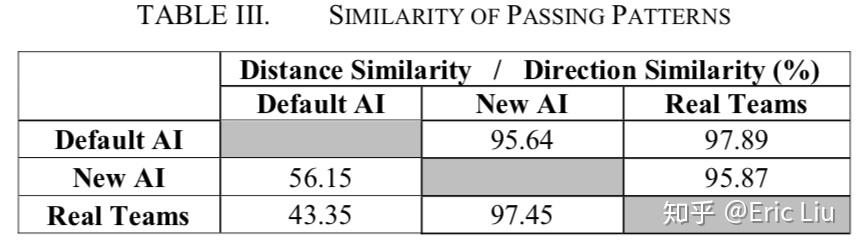
可以看到原AI在传球距离上一点都不像人,但在传球方向上还挺接近。关于表3,问题是,余弦相似度为啥不是对称的?
本文就结束了,感觉是您不能做充分点再跑去发文章?
作者Victor Khaustov, Maxim Mozgovoy,来自日本会津大学的“Active Knowledge Engineering Lab ”,发表在ICACT2020,对我来说也不是一个知名的会。









